LLMs (Restricted access)
This service is in a closed beta and is currently not available to all users.
| Name | Total Parameters | Quantization | Context Length | More info |
|---|---|---|---|---|
| Kimi-K2.5 | Total: 1T / Activated: 32B | BF16 | 262,144 tokens | https://huggingface.co/moonshotai/Kimi-K2.5 |
| Qwen3.5 | 27B | BF16 | 262,144 tokens | https://huggingface.co/Qwen/Qwen3.5-27B |
| Llama-3-3 | 70B | FP8 | 131,072 tokens | https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct |
| Qwen3 | 32B | BF16 | 30,000 tokens | https://huggingface.co/Qwen/Qwen3-32B |
To access the language model (LLM) service, you must have an active SCAYLE account with the appropriate permissions. These LLM access permissions must be requested via email to .
Next, access Caléndula with your user account (if you haven't accessed Caléndula before, follow this tutorial: System Access).
Once inside, you'll reach the cluster interface (frontend), from which you can make API requests directly.
ssh
[username@frontend1* ~]$IMPORTANT – To use the API via console or script, you must run the following command in the Caléndula terminal (otherwise you'll get a "Failed to connect to ..." error):
unset https_proxyAvailable ways to interact with the API:
- Via - Python script.
- Via - Terminal console.
Run the following script in Caléndula to interact with the API interactively (This is a guide/example script, adapt it to your needs):
SCRIPT: scayle_chat_api_client.py
GET API TOKEN
To make requests, you first need to generate an API token. You can obtain it as follows:
curl -X 'POST' \
'https://chat.scayle.es/api/v1/auths/ldap' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"user": "YOUR_SCAYLE_USER",
"password": "YOUR_SCAYLE_PASSWORD"
}'The response will be a JSON containing the token field. Use this value to authenticate and manage future API interactions.
{
"id":"*****",
"email":"*****",
"name":"*****",
"role":"user",
"profile_image_url":"/user.png",
"token":"COPY_YOUR_TOKEN",
"token_type":"Bearer"
...
}GET MODELS
Once authenticated, you will have access to public models available to all SCAYLE users. If you have additional access to private models, SCAYLE admins will assign those permissions. If after some time you do not see the private models, notify support at , as this process is manual and reviewed periodically.
To check the models available to you, execute the following API call:
curl -H "Authorization: Bearer PASTE_YOUR_TOKEN" https://chat.scayle.es/api/modelsYou will receive a JSON response where the field id contains the unique identifiers for each model. These IDs will be used to make inference calls.
{
"data": [
{
"id": "MODEL_ID",
"name": "MODEL_NAME",
"object": "model",
...
}
]
}MAKE AN INFERENCE
To perform an inference, send the following request:
- Set the model parameter to the ID obtained previously.
- After a few seconds, you will receive a response generated by the selected model.
curl -X POST https://chat.scayle.es/api/chat/completions \
-H "Authorization: Bearer PASTE_YOUR_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"model": "MODEL_ID",
"messages": [
{
"role": "user",
"content": "Tell me something about ..."
}
]
}'MAKE AN INFERENCE WITH CUSTOM SYSTEM PROMPT
curl -X POST https://chat.scayle.es/api/chat/completions \
-H "Authorization: Bearer PASTE_YOUR_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"model": "MODEL_ID",
"messages": [
{
"role": "system",
"content": "You are an assistant ..."
},
{
"role": "user",
"content": "Tell me something about ..."
}
]
}'Access to chat.scayle.es and enter the username and password of SCAYLE.
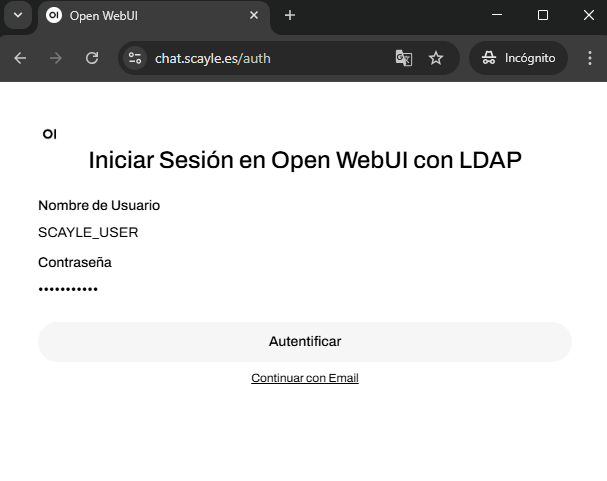
Find the desired model. If any requested model is not visible, contact indicating the problem.
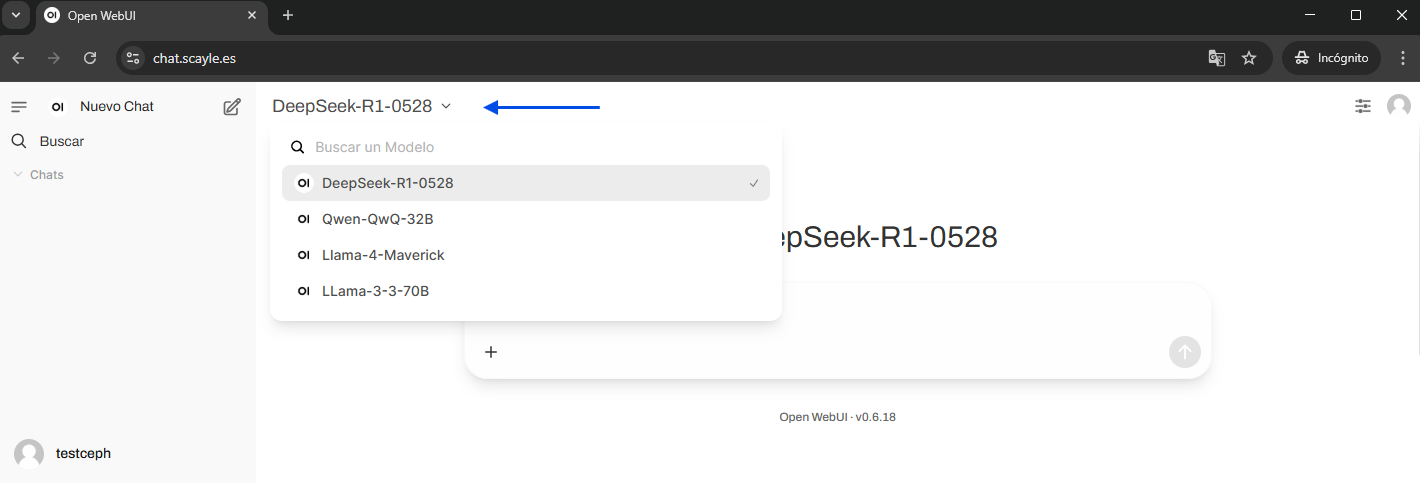
In the text field, enter the message for the inquiry and send it.